
java的内存分配策略
1、Java 程序运行时的内存分配策略有三种:
(1) 静态分配
(2) 栈式分配
(3) 堆式分配
2、对应的三种存储策略使用的内存空间如下:
(1) 静态存储区(也称方法区)
主要存放静态数据、全局 static 数据和常量。这块内存在程序编译时就已经分配好,
并且在程序整个运行期间都存在。
(2) 栈区
当方法被执行时,方法体内的局部变量都在栈上创建,并在方法执行结束时这些局部变量
所持有的内存将会自动被释放。因为栈内存分配运算内置于处理器的指令集中,效率很高,
但是分配的内存容量有限。
(3) 堆区
又称动态内存分配,通常就是指在程序运行时直接 new 出来的内存。这部分内存在不使
用时将会由 Java 垃圾回收器来负责回收。
(4) 栈与堆的区别:
在方法体内定义的(局部变量)一些基本类型的变量和对象的引用变量都是在方法的栈内存
中分配的。当在一段方法块中定义一个变量时,Java 就会在栈中为该变量分配内存空间,当超过
该变量的作用域后,该变量也就无效了,分配给它的内存空间也将被释放掉,该内存空间可以被
重新使用。
堆内存用来存放所有由 new 创建的对象(包括该对象其中的所有成员变量)和数组。在堆中分
配的内存,将由 Java 垃圾回收器来自动管理。在堆中产生了一个数组或者对象后,还可以在栈
中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,这个特殊的变
量就是我们上面说的引用变量。我们可以通过这个引用变量来访问堆中的对象或者数组。
(5) 结论:
局部变量的基本数据类型和引用存储于栈中,引用的对象实体存储于堆中。—— 因为它们属于方法中的变量,生命周期随方法而结束。
成员变量全部存储与堆中(包括基本数据类型,引用和引用的对象实体)—— 因为它们属于类,类对象终究是要被 new 出来使用的。
3、垃圾回收的算法有哪些?
① 引用计数法:原理是在此对象有个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回收时,只收集计数为0的对象.此算法的最致命的无法处理循环引用的问题
②: 标记-清除 :此算法分两个阶段,第一阶段从引用的根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除,此算法需要暂停应用,同时产生内存碎片
③: 复制算法 此算法把内存划分为两个相等的区域,每次只使用一个区域,垃圾回收时,遍历当前使用的区域,把正在使用的对象复制到另一个区域中每次算法每次只处理正在使用的对象,因此复制的成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现”碎片问题”,此算法的缺点也很明显,需要两倍的内存空间
④: 标记-整理:此算法结合了”标记-清除”和:复制算法的两个的优点,也是分两个阶段,第一个阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,清除未标记的对象并且把存活的对象”压缩”到堆的其中一块,按顺序排放,,此算法避免”标记-清除”的碎片问题,同时也避免”复制”的空间问题
4。root搜索算法中,哪些可以作为root?
- 被启动类(bootstrap加载器)加载的类和创建的对象
- JavaStack中引用的对象(栈内存中引用的对象)
- 方法区中静态引用
(1.jvm栈的栈帧中的本地变量表的引用 2.方法区静态属性引用 3.方法区中的常量引用 4.本地方法引用)
5、Java 是如何管理内存
Java 的内存管理就是对象的分配和释放问题。在 Java 中,程序员需要通过关键字 new 为
每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。另外,对象的
释放是由 GC 决定和执行的。在 Java 中,内存的分配是由程序完成的,而内存的释放是由 GC
完成的,这种收支两条线的方法确实简化了程序员的工作。但同时,它也加重了JVM的工作。
这也是 Java 程序运行速度较慢的原因之一。因为,GC 为了能够正确释放对象,GC 必须监控
每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC 都需要进行监控。监视
对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。
6、什么是 Java 中的内存泄露
在 Java 中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是
可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再
使用这些对象。如果对象满足这两个条件,这些对象就可以判定为 Java 中的内存泄漏,这些对象
不会被 GC 所回收,然而它却占用内存。
对象被回收的条件
- 可达性分析,该对象没有与GC Roots相连接的引用链,将进行如下操作
- 如果对象还没有执行finalize()方法,就会被放入F-Queue中
- 当GC触发时,Finalizer线程会F-Queue中的对象的finalize()方法
- 执行完finalize()方法后,会再次判断对象是否可达,如果不可达,才会被回收(所以对象可以通过在finalize()中将自己连接上某个GC Root链的方式来拯救自己)
java集合
- 1.List:ArrayList、LinkedList、Vector、CopyOnWriteArrayList
- 2.Set:HashSet、TreeSet、LinkedHashSet、CopyOnWriteArraySet、EnumSet
- 3.Map:HashMap、TreeMap、LinkedHashMap、HashTable、ConcurrentHashMap、WeakHashMap、EnumMap
- 4.Queue:ArrayBlockingQueue、LinkedBlockingQueue、DelayQueue、PriorityBlockingQueue、PriorityQueue。
栈:Stack<E> extends Vector<E>
// 或者
Deque<Integer> stack = new ArrayDeque<Integer>();
// 入栈
stack.push(E item)
// 出栈
stack.pop()
// 查看栈顶元素
stack.peek()
ArrayList
/** |
transient解释:其实是ArrayList在序列化的时候会调用writeObject(),直接将size和element写入ObjectOutputStream;反序列化时调用readObject(),从ObjectInputStream获取size和element,再恢复到elementData。原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
扩容为原来的1.5倍
CopyOnWriteArrayList
CopyOnWriteArrayList有点像线程安全的ArrayList.
其实它的原理简单概括起来就是读写分离.写操作是在一个复制的数组上进行的,读操作在原始数组中进行,读写是分离的.写操作的时候是加锁了的,写操作完成了之后将原来的数组指向新的数组.
下面我们简单看下add和get方法是如何实现写读操作的.
/** |
- 适用场景
因为每次写数据的时候都会开辟一个新的数组,这样就会耗费内存,而且加锁了,写的性能不是很好.而读操作是非常迅速的,并且还支持在写的同时可以读.
所以就非常适合读多写少的场景.
缺点
内存消耗大: 每次写操作都需要复制一个新的数组,所以内存占用是非常大的
数据不一致: 读数据的时候可能读取到的不是最新的数据,因为可能部分写入的数据还未同步到读的数组中.
对内存敏感和实时性要求很高的场景都不适合.CopyOnWriteArrayList为啥比Vector性能好?
在Vector内部,增删改查都进行了synchronized修饰,每个方法都要去锁,性能会大大降低.而CopyOnWriteArrayList只是把增删改加锁了,所以CopyOnWriteArrayList在读方面明显好于Vector.所以CopyOnWriteArrayList最好是在读多写少的场景下使用.
LinkedList
public class LinkedList<E> |
- AbstractSequentialList这个类提供了List的一个骨架实现接口,以尽量减少实现此接口所需的工作量由“顺序访问”数据存储(如链接列表)支持。对于随机访问数据(如数组),应使用AbstractList优先于此类。
- 实现了List接口,意味着LinkedList元素是有序的,可以重复的,可以有null元素的集合.
- Deque是Queue的子接口,Queue是一种队列形式,而Deque是双向队列,它支持从两个端点方向检索和插入元素.
- 实现了Cloneable接口,标识着可以它可以被复制.注意,ArrayList里面的clone()复制其实是浅复制(不知道此概念的赶快去查资料,这知识点非常重要).
实现了Serializable 标识着集合可被序列化。
LinkedList底层是链表结构:
- 插入和删除比较快(O(1)),查询则相对慢一些(O(n))
- 因为是链表结构,所以分配的空间不要求是连续的
private static class Node<E> { |
// LinkedList 当做队列使用 |
HashMap
- 存储结构
JDK 1.7
内部是以数组的形式存储了Entry对象,而每个Entry对象里面有key和value用来存值.它里面包含了key、value、next、hash四个字段,其中next字段是用来引用下一个Entry的(相同的hash值会被放入同一个链表中).数组中的每个位置都是一条单链表(也可以称之为桶),数组中的元素的表头.解决冲突的方式是拉链法,同一条单链表中的Entry的hash值是相同的.
transient Entry<K,V>[] table; |
JDK 1.8
存储结构也是数组,只不过将Entry换了个名字叫Node.1.7中hash值相同的是放单链表中,1.8也是,当这个单链表的长度超过8时,会转换成红黑树,增加查找效率.
- 负载因子和阈值
/** |
HashMap的默认大小是16,默认负载因子是0.75,意思是当存的元素个数超过16*0.75时就要对数组扩容,这里的阈值就是16*0.75=12.负载因子就是用来控制什么时候进行扩容的.
阈值 = 当前数组长度*负载因子
每次扩容之后都得重新计算阈值.默认的数组长度是16,默认的负载因子是0.75这些都是有讲究的.在元素个数达到数组的75%时进行扩容是一个比较折中的临界点,如果定高了的话hash冲突就很严重,桶就会很深,查找起来比较慢,定低了又浪费空间.一般情况下,还是不会去定制这个负载因子.
拉链法工作原理
每次新存入一个新的键值对时,首先计算Entry的hashCode,用hashCode%数组长度得到所在桶下标,然后在桶内依次查找是否已存在该元素,存在则更新,不存在则插入到桶的头部.HashMap 1.7和1.8区别
- JDK1.7用的是头插法,JDK1.8及置换是尾插法. 且1.7插入时候顺序是与原来相反的,而1.8则还是原来的顺序
- JDK1.7是数组+链表,JDK1.8是数组+链表+红黑树
- JDK1.7在插入数据之前进行扩容,JDK1.8是插入数据之后才扩容
- JDK1.7是Entry来表示节点,而JDK1.8是Node
- JDK1.7扩容和后存储位置是用hash & (length-1)计算来的,而JDK1.8只需要判断hash值新增参与运算的位是0还是1就能快速计算出扩容后该放在原位置,还是需要放在 原位置+扩容的大小值 .
- 计算hash值的时候,JDK1.7用了9次扰动处理,而JDK1.8是2次
ps: 红黑树查找元素,需要O(logn)的开销
- 下面来介绍下HashMap与Hashtable的区别:
- 1.实现:HashMap继承的类是AbstractMap类,而Hashtable继承的是Dictionary类,而Dictionary是一个过时的类,因此通常情况下建议使用HashMap而不是使用Hashtable
- 2.内部结构:其实HashMap与Hashtable内部基本都是使用数组-链表的结构,但是HashMap引入了红黑树的实现,内部相对来说更加复杂而性能相对来说应该更好
- 3.NULL值控制:通过前面的介绍我们知道Hashtable是不允许key-value为null值的,Hashtable对于key-value为空的情况下将抛出NullPointerException,而HashMap则是允许key-value为null的,HashMap会将key=null方法index=0的位置。
- 4.线程安全:通过阅读源码可以发现Hashtable的方法中基本上都是有
synchronized关键字修饰的,但是HashMap是线程不安全的,故对于单线程的情况下来说HashMap的性能更优于Hashtable,单线程场景下建议使用HashMap.
HashMap是绝大部分利用键值对存取场景的首选.多线程环境下,推荐使用ConcurrentHashMap.
数组+链表+红黑树
ConcurrentHashMap
- ConcurrentHashMap存在的意义?
有了HashMap和Hashtable为啥还需要ConcurrentHashMap?
HashMap本身不是线程安全的,不应该在多线程情况下使用!!!.
Hashtable是使用synchronized保证线程安全,当一个线程访问其中一个同步方法时,另外的线程是不能访问其同步方法的(竞争的是同一把锁).这样就会导致在put数据的时候,其他线程也不能get数据之类的操作.在线程竞争激烈的条件下,并发效率非常低.
既要多线程环境下使用,也要效率高? 选ConcurrentHashMap没错了.
- ConcurrentHashMap使用的是分段锁(Segment)技术,将数组分成很多段,每个分段锁维护着几个桶(HashEntry),然后修改数据的时候将这一段锁起来,其他线程这个时候要操作其他分段的数据也互不干扰.如果操作的不是同一分段,则线程间不存在竞争关系,大大提高了并发效率. 当然,有的朋友可能也想到了,有些时候可能需要跨段,比如调用size()方法,这个时候可能会锁整个表.
而在JDK1.8中抛弃了Segment分段锁机制,利用CAS+synchronized来保证并发更新的安全.
乐观锁是一种思想,CAS是这种思想的其中一种实现方式.当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其他线程都失败,失败的线程并不会挂起,而是被告知这次竞争失败,并可以再次尝试. CAS操作中包含3个操作数: 需要读写的位置(V)、进行比较的预期原值(A)和拟写入的新值(B).如果内存位置V的值与预期原值A相匹配,那么处理器会自动将该位置值更新为新值B.否则处理器不做任何操作.
TreeMap和LinkedHashMap
- TreeMap整体结构
TreeMap底层的数据结构是红黑树,和HashMap的红黑树结构是一样的.
TreeMap利用红黑树左节点小,右节点大的性质,根据key进行排序,使每个元素能够插入到红黑树中大小适当的位置,维护了key的大小关系,适用于key需要排序的场景.
因为底层使用的是平衡二叉树的结构,所以containsKey,get,put,put,remove等方法的时间复杂度都是log(n).
- LinkedHashMap的使用
HashMap是无序的,TreeMap可以根据key进行排序,LinkedHashMap可以维护插入的顺序.LinkedHashMap是HashMap的子类,它内部有一个双向链表维护着键值对的顺序.每个键值对即是位于哈希表中,也是位于双向链表中.LinkedHashMap支持两种顺序:
- 插入顺序: 先添加的在前面,后添加的在后面.修改操作是不影响顺序的
- 访问顺序: 在get/put操作之后,其对应的键值对会移动到链表末尾,表示最近使用到的.而链表的头部就是最久没有被访问到的.
HashSet和TreeSet
HashSet
HashSet里面维护了一个不含重复元素的集合,实现比较简单,就是通过HashMap来实现的.TreeSet
TreeSet大致的结构是和HashSet相似,底层的数据结构是TreeMap,所以继承了TreeMap key能够排序的功能,迭代的时候也可以按照key的顺序排序进行迭代.HashSet和TreeSet的区别
- HashSet保存的数据是无序的,TreeSet保存的数据是有序的.
- TreeSet保存自定义类对象的时候,必须实现Comparable接口,不实现就无法区分大小关系,无法排序.HashSet存对象的时候,判断其元素是否重复的依据是hashCode()和equals().
Android中的Bundle,SparseArray和ArrayMap
- Bundle
Android为什么要设计Bundle而不是直接使用HashMap来直接进行数据传递?
Bundle内部是由ArrayMap实现的,ArrayMap在设计上比传统的HashMap更多考虑的是内存优化
Bundle使用的是Parcelable序列化,而HashMap使用Serializable序列化
- SparseArray
SparseArray是用来存储key-value组合的,类似HashMap.但是它只能存储key为int类型的,也就避免了key的装箱操作和分配空间.建议使用SparseArray<V>替换HashMap<Integer,V>.
还有就是SparseArray是专门设计来节省空间的,所以它里面的数据存储得非常紧凑.key和value都是单独用一个数组来存储的,并且数组是按大小排好序了的,每次增删改查等操作都是用二分查找来进行定位位置的.
可以看到SparseArray比HashMap少了基本数据的自动装箱操作,而且不需要额外的结构体,单个元素存储成本低,在数据量小的情况下,随机访问的效率很高.但是缺点也显而易见,就是增删的效率比较低,在数据量比较大的时候,调用gc拷贝数组成本巨大.
除了SparseArray,Android还提供了SparseIntArray(int:int),SparseBooleanArray(int:boolean),SparseLongArray(int:long)等,其实就是把对应的value换成基本数据类型.
- ArrayMap
ArrayMap是一种通用的key-value映射的数据结构,和SparseArray类似.但是SparseArray只能存储int类型的key,而ArrayMap可以存储其他类型的key.如果你没有见过它也没关系,你肯定用过它.Bundle底层就是用的这玩意儿存储的数据.它底层不使用SparseArray可能就是因为它的key只能是int类型.
ArrayMap与传统的HashMap不同,它的数据结构是两个数组,一个数组(mHashes)用来存放key的hashcode,一个数组(mArray)用来存放key和value.你没看错,mArray数组里面即存放了key,也存放了value
ArrayMap在put/remove时,和SparseArray基本是一致的,也是通过二分查找求数组索引,然后再执行相应的操作.不同的是ArrayMap的扩容机制和缩容机制.
在put需要扩容时,如果容量小于4就给4,小于8就给8,其次就是扩容1.5倍.之所以给4或8是因为可以利用缓存的ArrayMap对象;在remove时,如果数组长度大于8但是存储的数据不足数据大小的1/3时,就会缩容,mSize小于等于8则设置新大小为8,否就设置为mSize的1.5倍,也就是说在内存使用量不足1/3时,内存数据收紧50%.
除了 put 方法,ArrayMap 和 SparseArray 都有一个 append 方法,它和 put 很相似,append 的差异在于该方法不会去做扩容操作,是一个轻量级的插入方法。在明确知道肯定会插入队尾的情况下使用 append 性更好,因为 put 一上来就做二分查找,时间复杂度 O(logn),而 append 时间复杂度为 O(1)。
ArraySet 也是 Android 特有的数据结构,用来替代 HashSet 的,和 ArrayMap 几乎一致,包含了缓存机制、扩容机制等。
ArrayList和LinkedList区别
我们知道,通常情况下,ArrayList和LinkedList的区别有以下几点:
- ArrayList是实现了基于动态数组的数据结构,而LinkedList是基于链表的数据结构;
- 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;
- 对于添加和删除操作add和remove,一般大家都会说LinkedList要比ArrayList快,因为ArrayList要移动数据。但是实际情况并非这样,对于添加或删除,LinkedList和ArrayList并不能明确说明谁快谁慢
- 针对for循环,ArrayList比LinkedList速度快,因为LinkedList没有实现
RandomAccess接口,需要从头或者从尾开始遍历到指定位置。如果都使用迭代器遍历的话,双方时间差不多。
关于第三条:ArrayList在添加和删除,如果未出现扩容的情况下,ArrayList快,这是因为:当 ArrayList 在添加元素到数组中间时,有一部分数据需要复制重排,效率就不是很高,那为啥 LinkedList 比它还要低呢?这是因为 LinkedList 把元素添加到中间位置的时候,需要在添加之前先遍历查找,这个查找的时间比较耗时。更多详细区别可以看这篇文章 https://blog.csdn.net/javageektech/article/details/108162342
// 使用Iterator遍历没有实现 RandomAccess的数据结构 |
HashMap、concurrentHashMap、HashTable的区别
HashMap是基于哈希表实现的,每一个元素都是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
HashMap、HashTable区别
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高。
ConcurrentHashMap是线程安全的HashMap的实现。同样是线程安全的类,它与HashTable在同步方面有什么不同呢?
ConcurrentHashMap与HashTable的区别
ConcurrentHashMap基于concurrentLevel划分出了多个Segment来对key-value进行存储,从而避免每次锁定整个数组,在默认的情况下,允许16个线程并发无阻塞的操作集合对象,尽可能地减少并发时的阻塞现象。
ConcurrentHashMap使用Lock锁住部分数组,而HashTable则是锁住整个数组,所以在多线程的环境中,相对于HashTable,ConcurrentHashMap会带来很大的性能提升!
而在JDK1.8中抛弃了Segment分段锁机制,利用CAS+synchronized来保证并发更新的安全.
Java中Vector和ArrayList的区别
首先看这两类都实现List接口,而List接口一共有三个实现类,分别是ArrayList、Vector和LinkedList。List用于存放多个元素,能够维护元素的次序,并且允许元素的重复。3个具体实现类的相关区别如下:
- ArrayList是最常用的List实现类,内部是通过
数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。 - Vector与ArrayList一样,也是通过
数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。 - LinkedList是用
链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
关于ArrayList和Vector区别如下:
- ArrayList在内存不够时默认是扩展50% + 1个,Vector是默认扩展1倍。
- Vector提供indexOf(obj, start)接口,ArrayList没有。
- Vector属于线程安全级别的,但是大多数情况下不使用Vector,因为线程安全需要更大的系统开销。
深拷贝or浅拷贝
在java语言中,有几种方式可以创建对象呢?
- 1 使用new操作符创建一个对象
- 2 使用clone方法复制一个对象
那么这两种方式有什么相同和不同呢?
new操作符的本意是分配内存。程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。
而clone在第一步是和new相似的,都是分配内存,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域, 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。
Person p = new Person(23, "zhang"); |
这种是复制引用
如果两个Person对象的name的地址值相同, 说明两个对象的name都指向同一个String对象, 也就是浅拷贝, 而如果两个对象的name的地址值不同, 那么就说明指向不同的String对象, 也就是在拷贝Person对象的时候, 同时拷贝了name引用的String对象, 也就是深拷贝。验证代码如下:
Person p = new Person(23, "zhang"); |
clone是浅拷贝的
序列化属于深拷贝
更多关于java拷贝知识参考这篇文章: https://juejin.cn/post/6844903806577164302
java引用类型
| 引用类型 | 被垃圾回收时间 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 | 从来不会 | 对象的一般状态 | JVM停止运行时终止 |
| 软引用 | 在内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 | 在垃圾回收时 | 对象缓存 | gc运行后终止 |
| 虚引用 | Unknown | Unknown | Unknown |
强引用是使用最普遍的引用:
Object o=new Object(); 特点:不会被GC
将对象的引用显示地置为null:o=null; // 帮助垃圾收集器回收此对象
软引用用来描述一些还有用但是并非必须的对象,在Java中用java.lang.ref.SoftReference类来表示。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象。因此,这一点可以很好地用来解决OOM的问题,并且这个特性很适合用来实现缓存:比如网页缓存、图片缓存等
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象
虚引用也称为幻影引用:一个对象是都有虚引用的存在都不会对生存时间都构成影响,也无法通过虚引用来获取对一个对象的真实引用。唯一的用处:能在对象被GC时收到系统通知,JAVA中用PhantomReference来实现虚引用。
android中的位运算
https://juejin.im/post/5c51f308e51d45141a1f2f2c
Java 内存模型(Java Memory Model ,JMM)
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
而JMM就作用于工作内存和主存之间数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。
主内存和工作内存与JVM内存结构中的Java堆、栈、方法区等并不是同一个层次的内存划分,无法直接类比。《深入理解Java虚拟机》中认为,如果一定要勉强对应起来的话,从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分。工作内存则对应于虚拟机栈中的部分区域
总结下,JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性和有序性。
Java内存模型的实现
了解Java多线程的朋友都知道,在Java中提供了一系列和并发处理相关的关键字,比如volatile、synchronized、final、concurren包等。其实这些就是Java内存模型封装了底层的实现后提供给程序员使用的一些关键字。
其实,原子性问题,可见性问题和有序性问题。是人们抽象定义出来的。而这个抽象的底层问题就是前面提到的缓存一致性问题、处理器优化问题和指令重排问题等
- 原子性是指在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。
- 可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
- 有序性即程序执行的顺序按照代码的先后顺序执行。
- 原子性
在Java中,为了保证原子性,提供了两个高级的字节码指令monitorenter和monitorexit。在synchronized的实现原理文章中,介绍过,这两个字节码,在Java中对应的关键字就是synchronized。
因此,在Java中可以使用synchronized来保证方法和代码块内的操作是原子性的。
- 可见性
Java内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。
Java中的volatile关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。
除了volatile,Java中的synchronized和final两个关键字也可以实现可见性。只不过实现方式不同,这里不再展开了。
- 有序性
在Java中,可以使用synchronized和volatile来保证多线程之间操作的有序性。实现方式有所区别:
volatile关键字会禁止指令重排。synchronized关键字保证同一时刻只允许一条线程操作。
好了,这里简单的介绍完了Java并发编程中解决原子性、可见性以及有序性可以使用的关键字。读者可能发现了,好像synchronized关键字是万能的,他可以同时满足以上三种特性,这其实也是很多人滥用synchronized的原因。
但是synchronized是比较影响性能的,虽然编译器提供了很多锁优化技术,但是也不建议过度使用。
ReentrantLock与synchronized对比
- Synchronized
Synchronized是通过同步互斥来实现线程安全的;即同一时间只能有一个线程访问synchronized修饰的代码块或方法。其特性与功能如下:
- synchronized是java的关键字,由jvm支持。
- 支持重入,即一个线程在获取对象的锁以后可以再次对此对象上锁。
- 修饰普通方法,锁是当前实例对象;修饰静态方法,锁是当前类的class对象;包裹代码块,锁是括号中的对象。
- 不支持等待中断。
- synchronized是非公平的。
- ReentrantLock
ReentrantLock是一种非常常见的临界区处理手段,通过在执行代码前上锁保证同一时间只有一个线程能执行指定的代码块。ReentrantLock的特性与功能如下:
- ReentrantLock是java api层面的实现,有Unsafe支持。
- 支持重入。
- 支持公平锁、非公平锁,默认是非公平锁。公平锁指:
多个线程在等待同一个线程的锁时,必须按照申请所得时间顺序来获取锁。非公平锁指:在锁被释放时,任何一个等待锁的线程都有机会获取锁。 - 支持等待中断。例如:A线程获取对象O的锁, B线程等待获取O的锁,当B长时间无法获取锁时,B可以放弃获取锁。
- 锁可以绑定多个条件。线程进入临界区,却发现在某一条件满足之后才能执行,条件对象就是用来管理那些已经获得了锁,但是却不能做有用工作的线程。一个ReentrantLock对象可以同时绑定多个Condition对象。
ReentrantLock本质上是通过一个队列来完成同步的。因为每个Node与一个线程关联,只需要做好对队列节点的同步处理,既可以完成多线程的同步处理。
public class Test { |
通过以上代码我们可以发现,不同于synchronized,ReentrantLock需要开发手动在代码中加锁和解锁。
- 公平锁与非公平锁
公平锁:通过同步队列来实现多个线程按照申请锁的顺序获取锁。
默认情况下,synchronized和ReentrantLock都是非公平锁。但是ReentrantLock可以通过构造函数传参true,来创建公平锁,可以通过以下的部分源码。
synchronized是JVM虚拟机的实现, 而ReentrantLock是JDK实现的,是java.util.concurrent包中的锁。
- 单例的双重校验锁实现(面试必备)
public class Singleton { |
深入理解 AQS 和 CAS 原理
AQS 全称是 Abstract Queued Synchronizer,即抽象队列同步器,AQS内部基于CAS、LockSupport、自旋和双端等待队列实现的多线程同步工具,AQS它是一套实现多线程同步功能的框架。
AQS 在JDK源码中被大量使用到,尤其是在 JUC(Java Util Concurrent)中,比如ReentrantLock、CountDownLatch、ThreadPoolExecutor。理解 AQS 对我们理解 JUC 中其他组件至关重要,并且在实际开发中也可以通过自定义 AQS 来实现各种需求场景。
链接:https://www.jianshu.com/p/5ff4bfe546f3 https://juejin.cn/post/6844904167044038663
注解原理
继承 AbstractProcessor ,根据注解构建对象,将对象存入map。然后使用javapoet 遍历map输出到一个类中。这个类就保存了所有的注解对象的键值对
应用APP启动过程
应用app具体会运行到哪个进程,我们从一个app的启动入手分析。app的启动一般从该应用的桌面图标点击开始,调用startActivity(Intent), 再通过Binder IPC机制, 最终调用到AMS。AMS会执行如下操作:
- 1.通过PackageManager的resolveIntent()收集这个intent对象的指向信息.
- 2.通过grantUriPermissionLocked()方法来验证用户是否有足够的权限去调用该intent对象指向的Activity.
- 3.如果有权限, AMS会检查并在新的task中启动目标activity.
- 4.如果ProcessRecord是null, AMS调用startProcessLocked()方法来创建新的进程.
android崩溃
当应用崩溃时,默认会调用Thread类中设置的一个 UncaughtExceptionHandler 中的 uncaughtException方法,所以我们只要实现一个UncaughtExceptionHandler对象,在其对应方法中实现对崩溃信息的保存或者上传即可。
异常分类
Throwable是Java语言中所有错误或异常的超类。下一层分为Error和Exception
Error类是指Java运行时系统的内部错误和资源耗尽错误。应用程序不会抛出该类对象。如果出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。Exception又有两个分支,- 一个是运行时异常
RuntimeException,如:NullPointerException、ClassCastException; - 一个是检查异常
CheckedException,如I/O错误导致的IOException、SQLException。
- 一个是运行时异常
RuntimeException是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。派生RuntimeException的异常一般包含几个方面:
- 1、错误的类型转换
- 2、数组访问越界
- 3、访问空指针
如果出现RuntimeException,那么一定是程序员的错误
检查异常CheckedException一般是外部错误,这种异常都发生在编译阶段,Java编译器会强制程序去捕获此类异常,即会出现要求你把这段可能出现异常的程序进行try catch,该类异常一般包括几个方面:
1、试图在文件尾部读取数据
2、试图打开一个错误格式的URL
3、试图根据给定的字符串查找class对象,而这个字符串表示的类并不存在
RuntimeException:在定义方法时不需要声明会抛出RuntimeException, 在调用这个方法时不需要捕获这个RuntimeException;总之,未检查异常不需要try…catch…或throws 机制去处理
CheckedException:定义方法时必须声明所有可能会抛出的exception; 在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去
总之,一个方法必须声明所有的可能抛出的受检异常;未检查异常要么不可控制(Error),要么应该避免(RuntimeException)。如果方法没有声明所有的可能发生的受检异常,编译器就会给出错误信息
Exception 和 Error 区别
Exception和Error都是继承了Throwable类,在Java中只有Throwable类型的实例才可以被抛出(throw)或者捕获,它是异常处理机制的基本组成类型.
Exception和Error体现了Java平台设计者对不同异常情况的分类,Exception是程序正常运行中,可以预料的意外情况,可能并且应该捕获,进行相应的处理.
Error是指正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序处于非正常状态,不可恢复状态.既然是非正常情况,所以不便于也不需要捕获,常见的如OutOfMemoryError之类的都是Error的子类.
Exception又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源码里必须显式地进行捕获处理,这里是编译期检查的一部分.不检查异常就是所谓的运行时异常,类似NullPointerException,ArrayIndexOutOfBoundsExceptin之类的,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求.
ClassNotFoundException 和 NoClassDefFoundError 区别
需要注意到的是一个是Exception一个是Error.
Java支持使用Class.forName方法来动态加载类,任意一个类的类名如果被作为参数传递给这个方法都将导致该类被加载到JVM内存中,如果这个类在类路径中没有被找到,那么此时就会在运行时抛出ClassNotFountException异常.
如果JVM或者ClassLoader实例尝试加载(可能通过正常的方法调用,也可能是使用new来创建新的对象)类的时候找不到类的定义.要查找的类在编译的时候是存在的,运行的时候却找不到类,这个时候就会导致NoClassDefFoundError.造成该问题的原因可能是打包过程中漏掉了部分类,或者jar包出现了损毁或者篡改.解决这个问题的方法是查找那些在开发期间存在于类路径但运行期间却不在类路径下的类.
Java多线程sleep和wait的区别
使用方面:
从使用的角度来看sleep方法是Thread线程类的方法,而wait是Object顶级类的方法。
sleep可以在任何地方使用,而wait只能在同步方法和同步块中使用。CPU及锁资源释放:
sleep、wait调用后都会暂停当前线程并让出CPU的执行时间,但不同的是sleep不会释放当前持有对象的锁资源,到时间后会继续执行,而wait会释放所有的锁并需要notify/notifyAll后重新获取到对象资源后才能继续执行。- 异常捕获方面:
sleep需要捕获或者抛出异常,而notify/notifyAll则不需要,但是wait方法需要捕获 InterruptedException。
简述jvm中默认的classLoader与功能
- 1.Bootstrap ClassLoader:负责加载java基础类,主要是 %JRE_HOME/lib/ 目录下的rt.jar、resources.jar、charsets.jar和class等
- 2.Extension ClassLoader:负责加载java扩展类,主要是 %JRE_HOME/lib/ext 目录下的jar和class
- 3.App ClassLoader:负责加载当前java应用的classpath中的所有类。
- 4.classloader 加载类用的是全盘负责双亲委托机制。
- 1.所谓全盘负责,即是当一个classloader加载一个Class的时候,这个Class所依赖的和引用的所有 Class也由这个classloader负责载入,除非是显式的使用另外一个classloader载入。所以,当我们自定义的classloader加载成功了 com.company.MyClass以后,MyClass里所有依赖的class都由这个classLoader来加载完成。
- 2.双亲委托,是指子类加载器如果没有加载过该目标类,就先委托父类加载器加载该目标类,只有在父类加载器找不到字节码文件的情况下才从自己的类路径中查找并装载目标类。
重写的特性
- 1.方法名相同,参数类型和顺序相同
- 2.子类返回类型小于等于父类方法返回类型。即:子类返回的类型要为父类的子类
- 3.子类抛出异常小于等于父类方法抛出异常。即:子类抛出的异常类型要为父类的子类
- 4.子类访问权限大于等于父类方法访问权限。
理解Serializable和Parcelable
我们日常用到的有二种场景。
- 1.数据的持久化保存,这里主要是指保存到文件
- 2.Android页面间数据的传递
第一种情况两者耗时差不多
第二种情况intent putExtra中添加实现了Serializable接口的对象时。Parcel会将Serializable先序列化为字节数组,然后写入,所以这中间就进行了二次序列化,性能肯定比Parcelable要低很多。所以如果我们的场景是界间传值的话,Parcelable是首选。
自行决定哪些需要字段需要序列化
1.继承Parcelable的类,在writeToParcel 方法中由开发者自己决定哪些字段参与初始化
2.Serializable可以使用
transient关键字来忽略一些不需要参与序列化的字段,也可以重写writeObject和readObject二个方法来替代默认的序列化调用。JDK中有很多这样的类,比如ArrayList,HashMap,都是重写了writeObject方法。
为什么HashMap要自定义序列化逻辑呢?我想可能的原因是,存储数据的数组table,一般都是不满的(因为HashMap的负载因子默认0.75,超过就会扩容),里面肯定会有很多null,如果是默认的序列化,这些null也会被被序列化,显然这些null是没有必要的做序列化的
Activity 中的 onAttachedToWindow,View 的 onAttachedToWindow和 RecyclerView.Adapter 的 onViewAttachedToWindow
- Activity 中的 onAttachedToWindow 就是在 View 附加到 window 上的时候进行回调,而 onDetachedFromWindow() 就刚好相反。是在OnResume之后回调,但是在 onAttachedToWindow() 回调的时候,不能拿到 View 的宽高
- View 的 onAttachedToWindow 的调用时机会发生在 onMeasure() 之前。我们在自定义 View 的时候,某些比较重量级的资源,而且不能与其他 View 通用的时候,就可以重写这两个方法,并在 onAttachedToWindow() 中进行初始化,onDetachedFromWindow() 方法里释放掉。
- RecyclerView.Adapter 的 onViewAttachedToWindow 和onViewDetachedToWindow。这两个方法在列表布局的时候,用作曝光埋点非常好用,当 Adapter 创建的 View 被窗口分离(即滑动离开了当前窗口界面的)的时候,onViewDetachedToWindow() 会被直接回调,反之,在列表项 View 在被滑动进屏幕的时候,onViewAttachedToWindow() 会立马被调用。
RecyclerView.Adapter 的onBindViewHolder和onViewRecycled(RecyclerView.ViewHolder holder)可以成对使用,表示ViewHolder绑定和解绑,但是这两个方法不适合用来做曝光埋点。因为RecyclerView的一二级缓存的重复使用不会回调onBindViewHolder。
RecyclerView.Adapter 咋还有一个 onAttachedToRecyclerView。根据源码我们可以发现,onAttachedToRecyclerView() 是在 setAdapter() 的时候触发。
我的 RecyclerView.Adapter 的 onViewAttachedToWindow 为啥没起作用?
可能会有小伙伴会遇到这个问题,在遇到这个问题前,先检查一下你这个 RecyclerView 是否是一个正常滚动的 View,你如果是被别人嵌套滚动,把自己设置了 isNestedScrollingEnabled 为 false 的话,那你都失去了 Recyclerview 的功用了,那自然是不行的。
可能又有小伙伴说了,由于需求历史原因,我就是用了 NestedScrollView 嵌套了 Recyclerview,并禁掉了 Recyclerview 的滑动功能,但又想做上面的曝光埋点功能,那如何是好?
如果是这样的话,大概你就只能通过类似 View 的 getGlobalVisibleRect() 这样的方法来判断 View 的可见性来处理了。关于 View 的可见性分析,这里就点到为止,大家就自行 Google 吧。
LiveData为何能感知生命周期
LiveData是一个数据持有类,它可以通过添加观察者被其他组件观察其变更
LiveData的特点:
- 1)采用观察者模式,数据发生改变,可以自动回调(比如更新UI)。
- 2)不需要手动处理生命周期,不会因为Activity的销毁重建而丢失数据。
- 3)不会出现内存泄漏。
- 4)不需要手动取消订阅,Activity在非活跃状态下(pause、stop、destroy之后)不会收到数据更新信息。
LiveData 的生命周期感知是由Lifecycle来实现的。ComponentActivity 实现了LifecycleOwner,并添加了一个ReportFragment,通过fragment的生命周期回调来完成生命周期的状态切换,并通知给注册的 LifecycleObserver接口
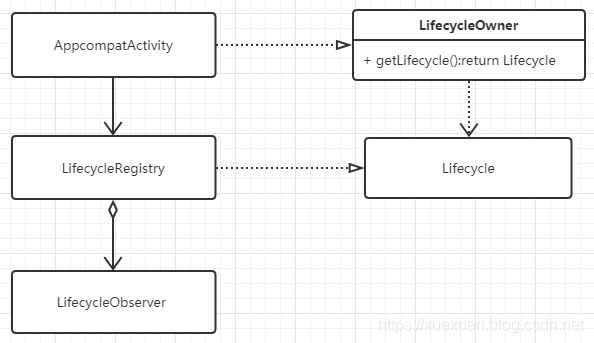
自定义的Activity都继承自AppCompatActivity ,AppCompatActivity 实现了LifecycleOwner接口,同时持有实现了Lifecycle的LifecycleRegistry对象,这个对象就可以将其理解为观察者模式中的Subject,LifecycleRegistr聚合多个LifecycleObserver,生命周期改变时通知LifecycleObserver进行相应的方法调用。
ViewModel
ViewModel旨在以注重生命周期的方式存储和管理界面相关的数据(配合它里面的livedata)。
- 1.1 将Activity的UI处理和数据处理分离,分开管理,解耦且高效。
- 1.2 ViewModel在屏幕旋转等系统配置更改后被继续保留,避免再次请求数据,浪费网络资源。重建该 Activity时,它接收的ViewModel实例与之前的Activity持有的ViewModel相同。只有当Activity真正销毁时,框架才会调用getViewModelStore().clear()清除所有的ViewModel。
- 1.3 避免页面销毁后,数据返回后刷新界面导致crash,例如页面发起请求后,数据还没返回就关闭activity,数据返回后,刷新界面,因view不存在而crash。
- 1.4 两个Fragment可以使用其Activity的ViewModel来处理通信。
- 1.5 和onSaveInstanceState()对比,onSaveInstanceState()仅适合可以序列化再反序列化的少量数据,而不适合数量可能较大的数据,如用户列表或位图。
- 1.6 ViewModelScope,为应用中的每个ViewModel定义了ViewModelScope。如果ViewModel已清除,则在此范围内启动的协程都会自动取消。
原理
ViewModelProvider
ViewModelStoreOwner:是一个接口,只定义了一个方法:getViewModelStore()。同样ComponentActivity和Fragment实现了这个接口,所以我们在Activity或者Fragment中使用ViewModelProvider传入的this就可以了。
ViewModelStore:ViewModelStore主要是用来存储ViewModel对象的,内部有一个HashMap集合(HashMap<String, ViewModel> mMap)用来存储ViewModel对象。
ComponentActivity持有一个ViewModelStore,可以通过ViewModelStoreOwner中的getViewModelStore()方法获取。(为啥不直接在Activity获取ViewModelStore,再获取ViewModel呢?因为ViewModel要通过ViewModelProvider.Factory创建)
Factory:是一个接口,用来创建ViewModel的
Activity 可以调用ViewMode的方法,同时ViewModel通过LiveData变化的监听改变view
Kotlin单例
使用 object 关键字
object SomeSingleton{ |
转成java代码之后是:
public final class SomeSingleton { |
有对比就清晰了,Kotlin 的 object 关键字,在 Java 表现的特点如下:
- 类用 final 标记,标识不可变性。
- 内部声明一个 static final 的当前类的对象 INSATNCE。
- 在静态代码块中,进行 INSTANCE 对象的初始化。
可以看到,在 Kotlin 的 object 中,是使用类的初始化锁来保证线程安全的。
那什么是类的初始化锁?简单来说, JVM 在类的初始化阶段(即在 Class 被加载后,且被线程使用之前),会执行类的初始化,在初始化期间,JVM 会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化,避免多线程调用时,引发线程安全的问题。
怎样保证任务顺序执行
- 观察者模式,使用队列保存注册的观察者,按队列顺序依次执行
- 责任链模式,参考view的事件分发、有序广播、Okhttp拦截器
怎么统计app启动过程中的方法
AMS 方法进入的时候埋点,方法退出的时候埋点
Fragment栈原理
fragment的切换切换都是通过getFragmentManager(),以beginTransaction()开始,commit() / commitNow() / commitAllowingStateLoss() 结束。getFragmentManager().beginTransaction().setCustomAnimations(R.anim.active_right_in, 0, 0, R.anim.active_right_out).add(android.R.id.content, fragment, "DebugConfigFragment").addToBackStack(getClass().getSimpleName()).commitAllowingStateLoss();
beginTransaction() 会返回一个FragmentTransaction的实现 -》 BackStackRecord
public FragmentTransaction beginTransaction() {
return new BackStackRecord(this);
}
- FragmentTransaction 是一个抽象类,内部定义了操作fragment栈的各种方法
- BackStackRecord是FragmentTransaction的实现类
- 内部定义了一些常量int值,用作操作指令
- 同时内部有一个实体类 Op,Op类的实例会存储 fragment引用,对应的指令。
在 BackStackRecord 类中,我们以show和hide为例,每次show或hide都会创建一个对应的Op类,并持有了对应的fragment和指令:
public FragmentTransaction hide(@NonNull Fragment fragment) {
addOp(new Op(OP_HIDE, fragment)); // OP_HIDE 就定义在FragmentTransaction类中
return this;
}
public FragmentTransaction show(@NonNull Fragment fragment) {
addOp(new Op(OP_SHOW, fragment));
return this;
}
addOp()方法将新创建的指令加入到了 mOps(ArrayList)中:
ArrayList<Op> mOps = new ArrayList<>(); |
从FragmentTransaction 继承来的方法,比如show和hide这种只会向 mOps 中添加数据,真正消耗 mOps 操作的是 executeOps() 和 executePopOps() 方法:
void executeOps() { |
void executePopOps(boolean moveToState) { |
executeOps() 方法和 executePopOps() 方法遍历正好相反、相同指令对应的操作也正好相反。同时这两个方法都是在FragmentManager的commit() / commitNow() / commitAllowingStateLoss()这几个方法中触发的,篇幅有限,本文就不具体展开了。
32位和64位的区别
64位可以使用的虚拟内存空间更大,64位意味着操作系统和CPU将使用64位的指令集
虚拟内存(VSS OOM)
当前绝大部分系统已经是 64 位系统,无论是服务器、个人 PC、亦或是终端手机。64 位系统的进程地址空间分布中,如果是 3 级页表,内核栈和用户栈分别有 512G 的地址空间,如果是 4 级页表,内核栈和用户栈分别有 256TB 的地址空间,这个值远大于实际物理内存,使用耗尽的可能性也非常小。
而我们的问题,发生在 64 位的 Android 系统中,但却是 32 位的应用。
32 位应用的可用虚拟内存只有 4G。物理内存我们有非常多的机制去管理和控制它的使用量,但虚拟内存其实只是一个空头支票,所以可以理解说,在设计时,能申请的虚拟内存范围是很大的,一般远大于一个进程实际会用的物理内存,所以它不需要复杂的管理机制,从可用的资源中找一块空虚的即可。然而当下系统和应用附加的东西越来越多,手机上可用的物理内存也越来越多,甚至有十几 G 内存的手机,仅仅 4G 的地址空间,些许错误或者资源申请较多,便很容易出现 OOM。
所以总结起来有两个问题导致:
- 32 位系统的 4G 虚拟内存在当下资源消耗较多的情况下,已捉襟见肘。
- 虚拟内存没有防止碎片化等复杂的管理机制,出现碎片化等问题。
在32位的应用上,内存使用不合理时,会比较容易引发因虚拟内存不足而导致的白屏或OOM等问题。参考:https://cloud.tencent.com/developer/article/1797705
虚拟内存浅析
在多任务操作系统中,每个进程都拥有独立的虚拟地址空间,通过虚拟地址进行内存访问主要具备以下几点优势:
- 进程可使用连续的地址空间来访问不连续的物理内存,内存管理方面得到了简化。
- 实现进程与物理内存的隔离,对各个进程的内存数据起到了保护的作用。
- 程序可使用远大于可用物理内存的地址空间,虚拟地址在读写前不占用实际的物理内存,并为内存与磁盘的交换提供了便利。
重载和重写的区别
https://zhuanlan.zhihu.com/p/288278829
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可以修改 | 一定不能修改 |
| 异常 | 可以修改 | 可以减少或删除,一定不能抛出新的或者更广的异常 |
| 访问 | 可以修改 | 一定不能做更严格的限制(可以降低限制) |
重载方法之间的方法名是相同的,但方法签名不同
一定要注意的是方法重载时,方法返回值没有什么意义,是由方法名和参数列表决定的
方法名和形参数据类型列表可以唯一的确定一个方法,与方法的返回值一点关系都没有,这是判断重载重要依据,所以,以下的代码是不允许的
public long aaaa(){ |
类型签名又是另一种了,参考: https://cloud.tencent.com/developer/article/1870340?from=article.detail.1787542
再看一下类型签名:public void test1(){} test1()V
public void test2(String str) test2(Ljava/lang/String;)V
public int test3(){} test3()I
从以上三个例子,我们就可以很简单的看出一些小小的规律: JVM为我们提供的类型签名实际上是由 方法名(上文的例子为了简单没有写出全类名)、形参列表、返回值三部分构成的,基本形式就是: 全类名.方法名(形参数据类型列表)返回值数据类型
Java方法类型签名中特殊字符/字母含义
| 特殊字符 | 数组类型 | 特殊说明 |
|:——–:|:——-:|:——–:|
|V| void| 一般用于表示方法的返回值|
|Z |boolean||
|B| byte||
|C| char||
|S |short||
|I| int||
|J|long||
|F|float||
|D|double||
|[|数组| 以[开头,配合其他的特殊字符,表示对应数据类型的数组,几个[表示几维数组|
|L|全类名|引用类型 以 L 开头 ; 结尾,中间是引用类型的全类名|
android 中系统时间
参考: https://www.jianshu.com/p/dfa184764daa
System.currentTimeMillis()
我们一般通过它来获取手机系统的当前时间。事实上,它返回的值是系统时刻距离标准时刻(1970.01.01 00:00:00)的毫秒数。它相当于家里的“挂钟”一样,并不是十分精准,而且可以随意修改。所以它可能经常被网络或者用户校准。正是由于这个原因,这个方法获取的值不适合用来做时间间隔的统计。但是它适合用来获取当前日期,时刻等时间点相关的逻辑。
SystemClock.upTimeMillis()
这个值记录了系统启动到当前时刻经过的时间。但是系统深度睡眠(CPU睡眠,黑屏,系统等待唤醒)之中的时间不算在内。这个值不受系统时间设置,电源策略等因素的影响,因此它是大多数时间间隔统计的基础,例如Thread.sleep(long millis),Object.wait(long millis),System.nanoTime()等。系统保证了这个值只增长不下降,所以它适合所有的不包括系统睡眠时间的时间间隔统计。
SystemClock.elapsedRealtime() & SystemClock.elapsedRealtimeNanos
这个值与SystemClock.upTimeMillis()类似。它是系统启动到当前时刻经过的时间,包括了系统睡眠经过的时间。在CPU休眠之后,它依然保持增长。所以它适合做更加广泛通用的时间间隔的统计。
综上,如果想要避免用户修改时间,网络校准时间对时间间隔统计的影响,使用SystemClock类相关的方法就可以了,至于选择upTimeMillis()还是elapsedRealtime()就要根据自己的需求确定了。
系统还提供了几个时间控制相关的工具:
- 标准方法Thread.sleep(long millis) 和 Object.wait(long millis)是基于SystemClock.upTimeMillis()的。所以在系统休眠之后它们的回调也会延期,直到系统被唤醒才继续计时。并且这两个同步方法会响应InterruptException,所以在使用它们的时候必须要处理InterruptException异常。
- SystemClock.sleep(long millis) 与 Thread.sleep(long millis) 方法是类似的,只不过SystemClock.sleep(long millis) 不响应InterruptException异常。
Handler类的 postDelay()方法也是基于SystemClock.upTimeMillis()方法的。 - AlarmManager可以定时发送消息,即使在系统睡眠、应用停止的状态下也可以发送。我们在创建定时事件的时候有两个参数可以选择RTC和ELAPSED_REALTIME,它们对应的方法就是System.currentTimeMillis() ~ RTC,SystemClock.elapsedRealtime() ~ ELAPSED_REALTIME。这样一对应,它们的区别也就非常明显了。
子线程更新UI
下次如果有人问你 Android 中子线程真的不能更新 UI 吗? 你可以这么回答:
任何线程都可以更新自己创建的 UI。只要保证满足下面几个条件就好了
- 在 ViewRootImpl 还没创建出来之前
- UI 修改的操作没有线程限制。
- 在 ViewRootImpl 创建完成之后
- 1.保证「创建 ViewRootImpl 的操作」和「执行修改 UI 的操作」在同一个线程即可。也就是说,要在同一个线程调用 ViewManager#addView 和 ViewManager#updateViewLayout 的方法。
注:ViewManager 是一个接口,WindowManger 接口继承了这个接口,我们通常都是通过 WindowManger(具体实现为 WindowMangerImpl) 进行 view 的 add remove update 操作的。
- 2.对应的线程需要创建 Looper 并且调用 Looper#loop 方法,开启消息循环。
- 1.保证「创建 ViewRootImpl 的操作」和「执行修改 UI 的操作」在同一个线程即可。也就是说,要在同一个线程调用 ViewManager#addView 和 ViewManager#updateViewLayout 的方法。
有同学可能会问,保证上述条件 1 成立,不就可以避免 checkThread 时候抛出异常了吗?为什么还需要开启消息循坏?
- 条件 1 可以避免检查异常,但是无法保证 UI 可以被绘制出来。
- 条件 2 可以让更新的 UI 效果呈现出来
WindowManger#addView 最终会调用 WindowManageGlobal#addView 方法,进而触发ViewRootImpl#setView 方法,该方法内部会调用 ViewRootImpl#requestLayout 方法。
了解过 UI 绘制原理的同学应该知道 下一步就是 scheduleTraversals 了,该方法会往消息队列中插入一条消息屏障,然后调用 Choreographer#postCallback 方法,往 looper 中插入一条异步的 MSG_DO_SCHEDULE_CALLBACK 消息。等待垂直同步信号回来之后执行。
注:ViewRootImpl 有一个 Choreographer 成员变量,ViewRootImpl 的构造函数中会调用 Choreographer#getInstance(); 方法,获取一个当前线程的 Choreographer 局部实例。
使用子线程更新 UI 有实际应用场景吗?
Android 中的 SurfaceView 通常会通过一个子线程来进行页面的刷新。如果我们的自定义 View 需要频繁刷新,或者刷新时数据处理量比较大,那么可以考虑使用 SurfaceView 来取代 View。
java线程状态
- 初始状态(
NEW)
实现Runnable接口和继承Thread可以得到一个线程类,new一个实例出来,线程就进入了初始状态。
- 初始状态(
- 就绪状态(
RUNNABLE之READY)
就绪状态只是说你资格运行,调度程序(Cpu)没有挑选到你,你就永远是就绪状态。
调用线程的start()方法,此线程进入就绪状态。
当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。
当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。
锁池里的线程拿到对象锁后,进入就绪状态。
进入:调用Thread.start()
- 就绪状态(
- 运行中状态(
RUNNABLE之RUNNING)
线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一的一种方式。
- 运行中状态(
- 阻塞状态(
BLOCKED)
阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
进入:等待进入synchronized方法、等待进入synchronized块
退出:获取到锁
- 阻塞状态(
- 等待(
WAITING)
处于这种状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。
进入:Object.wait() Thread.join() LockSupport.park()
退出:Object.notify() Object.notifyAll() LockSupport.unpark(Thread)
- 等待(
- 超时等待(
TIMED_WAITING)
处于这种状态的线程不会被分配CPU执行时间,不过无须无限期等待被其他线程显示地唤醒,在达到一定时间后它们会自动唤醒。
进入:Thread.sleep(long) Object.wait(long) Thread.join(long) LockSupport.parkNanos() LockSupport.parkUnit()
退出:Object.notify() Object.notifyAll() LockSupport.unpark(Thread)
- 超时等待(
- 终止状态(
TERMINATED)
当线程的run()方法完成时,或者主线程的main()方法完成时,我们就认为它终止了。这个线程对象也许是活的,但是它已经不是一个单独执行的线程。线程一旦终止了,就不能复生。
在一个终止的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
进入:执行完成
- 终止状态(
同步队列与等待队列
Wait()与Notify()方法
wait(): 持有锁的线程调用wait()方法后,会一直阻塞,直到有别的线程调用notify()将其唤醒
notify(): 只能通知一个等待线程,唤醒任意一个处于wait线程
notifyall():将等待队列中的所有线程唤醒,并加入同步队列
任意一个object以及其子类对象都有两个队列
同步队列:所有尝试获取该对象Monitor失败的线程,都加入同步队列排队获取锁
等待队列:已经拿到锁的线程在等待其他资源时,主动释放锁,置入该对象等待队列中,等待被唤醒,当调用notify()会在等待队列中任意唤醒一个线程,将其置入同步队列的尾部,排队获取锁

同步队列状态
当前线程想调用对象A的同步方法时,发现对象A的锁被别的线程占有,此时当前线程进入同步队列。简言之,同步队列里面放的都是想争夺对象锁的线程。
当一个线程1被另外一个线程2唤醒时,1线程进入同步队列,去争夺对象锁。
同步队列是在同步的环境下才有的概念,一个对象对应一个同步队列。
线程等待时间到了或被notify/notifyAll唤醒后,会进入同步队列竞争锁,如果获得锁,进入RUNNABLE状态,否则进入BLOCKED状态等待获取锁。
参考:https://segmentfault.com/a/1190000038392244
静态方法传递Context会导致内存泄漏吗?
不会,解释如下:
Passing a context or any argument for that matter, to a method, whether it is static or not, will put that argument on the function stack. For the scope of that function the context will be kept on the stack. As soon as the function ends, the function stack is cleared, i.e. the context won’t leak! No exceptions to this! This is the whole pure synchronous function thing discussed previously.
If you pass a context to a method (static or not) and in that method you decide to run some background stuff you might leak. This is not a pure function.
You would leak if you are holding onto the context longer than it takes to finish executing the original method. Using anonymous inner classes for callbacks when doing background work is typically a culprit here because that callback is invoked after the original function ends. You should ask yourself how the callback can fire and access the context argument if the original function has concluded. Well a copy is created so you now are holding onto a context that outlives the scope of the original function and tada leak!
参考:https://www.reddit.com/r/androiddev/comments/d9khex/can_passing_context_to_static_method_cause_a/
Https 单向认证和双向认证
贴张https讲解比较全面的图: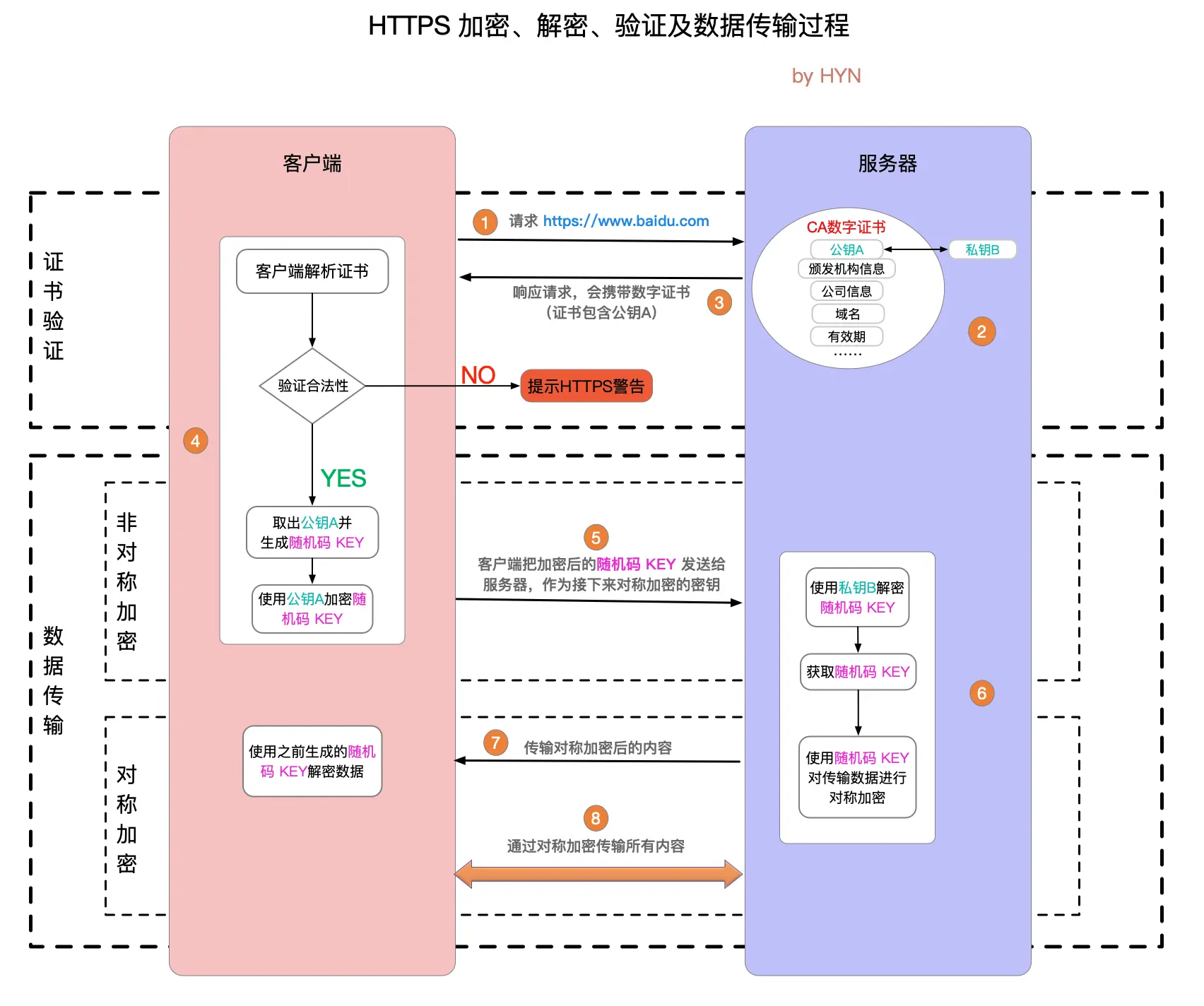
还可以参考下面的链接:
https://cloud.tencent.com/developer/article/1420302
除了tcp三次握手,还有ssl四次握手https://www.cnblogs.com/wangwenhui/p/14870881.html
https://segmentfault.com/a/1190000025126670
Activity启动流程主要包含几步?
我们以点击Launcher的一个icon为开始,整体扯一下Activity的启动过程,桌面其实就是LauncherApp的一个Activity
- 当点击Launcher的icon开始,Launcher进程会像AMS发送点击icon的启动信息(这些信息就是在AndroidMainifest.xml中
<intent-filter>标签定义的启动信息,数据由PackageManagerService解析出来) - AMS收到信息后会先后经过ActivityTaskManagerService->ActivityStartController->ActivityStarter内部类Request,然后把信息存到Request中,并通知Launcher进程让Activity休眠(补充个小知识点,这个过程会检测Activity在AndroidMainifest.xml的注册,如果没有注册就报错了)
- Launcher进程的ApplicationThread对象收到消息后调用handlePauseActivity()进行暂停,并通知AMS已经暂停。
实现细节:ActivityThread.sendMessage()通过ActivityThread的H类发送Handler消息,然后触发 mTransactionExecutor.execute(transaction),
执行过程中依赖ActivityClientRecord.mLifecycleState数值并通过ClientTransactionHandler抽象类的实现(ActivityThread)进行分发。
注 :ActivityClientRecord.mLifecycleState(-1 ~ 7分别代表 UNDEFINED, PRE_ON_CREATE, ON_CREATE, ON_START, ON_RESUME, ON_PAUSE, ON_STOP, ON_DESTROY, ON_RESTART) - AMS收到Launcher的已暂停消息后,会检查要启动的Activity所在的进程是否已经启动了,如果已经启动了就打开,如果未启动则通过Process.start(android.app.ActivityThread)来启动一个新的进程。
- 进程创建好以后,会调用ActivityThread.main(),初始化MainLooper,并创建Application对象。然后Instrumentation.newApplication()反射创建Application,创建ContextImpl通过Application的attach方法与Application进行绑定,最终会调用Instrumentation.callApplicationOnCreate执行Application的onCreate函数进行一些初始化的工作。完成后会通知AMS进程已经启动好了。
通知过程:通过IActivityManager.attachApplication(IApplicationThread thread, long startSeq),将Application对象传入AMS - AMS收到app进程启动成功的消息后,从ActivityTaskManagerService中取出对应的Activity启动信息, 并通过ApplicationThreadProxy对象,调用其scheduleTransaction(ClientTransaction transaction)方法,具体要启动的Activity都在ClientTransaction对象中。
- app进程的ApplicationThread收到消息后会调用ActiivtyThread.sendMessage(),通过H发送Handler消息,在handleMessage方法的内部又会调用 mTransactionExecutor.execute(transaction);具体参考第3步
最终调用performLaunchActivity方法创建activity和context并将其做关联,然后通过mInstrumentation.callActivityOnCreate()->Activity.performCreate()->Activity.onCreate()回调到了Activity的生命周期。
activity向Instrumentation请求创建
Instrumentation通过AMS在本地进程的IBinder接口,访问AMS,这里采用的跨进程技术是AIDL。
然后AMS进程一系列的工作,如判断该activity是否存在,启动模式是什么,有没有进行注册等等。
通过ClientLifeCycleManager,利用本地进程在系统服务进程的IBinder接口直接访问本地ActivityThread。
ApplicationThread是ActivityThread的内部类,IApplicationThread是在远程服务端的Binder接口
ApplicationThread接收到服务端的事务后,把事务直接转交给ActivityThread处理。
ActivityThread通过Instrumentation利用类加载器进行创建实例,同时利用Instrumentation回调activity的生命中周期
阻止activity重建时出现多个fragment
正常activity重建后,fragment系统会帮你重建一个,执行到onCreate 自己又会重建一个,所以会出现多个protected void onCreate(@Nullable Bundle savedInstanceState) {
if (savedInstanceState != null) {
savedInstanceState.putParcelable("android:support:fragments", (Parcelable)null);
}
}
intent传输数据大小限制
通过 intent 的 bundle 的源码可以看到它们都是实现了 Parcelable ,其实就是通过序列化来实现通信的。Parcelable 的底层使用了 Parcel 机制。传递实际上是使用了 binder 机制,binder 机制会将 Parcel序列化的数据写入到一个共享内存中,读取时也是 binder 从共享内存中读出字节流,然后 Parcel 反序列化后使用。这就是 Intent 或 Bundle 能够在 activity或者跨进程通信的原理。
这个共享内存就叫 Binder transaction buffer,这块内存有一个大小限制,目前是 1MB,而且共用的,当超过了这个大小就会报错(TransactionTooLargeException)。
Handler
Handler 构造方法:// Handler.java
public Handler(@Nullable Callback callback, boolean async) {
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
// Looper.java
public static Looper myLooper() {
return sThreadLocal.get();
}
// Looper.java
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed)); // 创建mQueue
}
// Looper.java
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
- 一个线程可以创建多个handler,但只会有一个Looper,因此也只会有一个MessageQueue。
- 如果子线程创建handler的时候没有调用
Looper.prepare()那么会抛出运行时异常
//MessageQueue.java |
在java层中,mPtr保存了nativeInit()返回的值,Looper和MessageQueue在java层和native层都有,但它们的功能并不是一一对应,此处native层的Looper与Java层的Looper没有任何的关系,只是在native层重实现了一套类似功能的逻辑。通过管道与epoll机制建立一套消息机制
在java层,没有消息时,会调用nativePollOnce方法进入阻塞。进入阻塞后可以通过超时唤起,也可以调用 natvieWake 主动唤起
//frameworks/base/core/jni/android_os_MessageQueue.cpp |
总结一下:
因为java层的消息机制是依赖native层的消息机制来实现的,而native层的消息机制是通过Linux的管道和epoll机制实现的,epoll机制是一种高效的IO多路复用机制, 它使用一个文件描述符管理多个描述符,java层通过mPtr指针也就共享了native层的epoll机制的高效性,当loop方法中取不到消息时,便阻塞在MessageQueue的next方法,而next方法阻塞在nativePollOnce方法,nativePollOnce方法通过JNI调用进入到native层中去,最终nativePollOnce方法阻塞在epoll_wait方法中,epoll_wait方法会让当前线程释放CPU资源进入休眠状态,等到下一个消息到达(mWakeEventFd会往管道写入字符)或监听的其他事件发生时就会唤醒线程,然后处理消息,所以就算loop方法是死循环,当线程空闲时,它会进入休眠状态,不会消耗大量的CPU资源。
Native层参考这两篇文章: https://www.jianshu.com/p/57a426b8f145
https://www.jianshu.com/p/c4e34c16aa45
为什么List<String>不能赋值给List<Object>
java在1.5的时候引入了泛型,虽然String是Object的子类,但是List<String> 并不是List<Object>的子类型,这叫做不支持协变(也有说型变)。
如何让java支持协变,List<String> 可以赋值给 List<Object>呢,下面这样写就可以List<? extends Object> list = new ArrayList<String>();
list.add("kotlin"); // 编译报错,不允许
在kotlin写法如下:val list: List<Any?> = ArrayList<String?>()
// 这里的List是一个接口类
public interface List<out E> : Collection<E> {
//...
// 没有add方法
}
add方法不能使用的原因就是将泛型声明为协变所需要付出的代价。
跟协变对立的是逆变,关键字是super或in(kotlin
这里再延伸一下,java中数组不支持泛型是协变的,kotlin中数组是支持泛型的,也就不再协变
更多的关于协变和逆变的介绍可以看我的这篇文章:Kotlin 与 Java 语言比较

本文链接:http://agehua.github.io/2022/02/13/Java-summary/

